 Ajándékozz éves hvg360 előfizetést!
Ajándékozz éves hvg360 előfizetést!
Bár a betanítás során még előre látható a mesterséges intelligencia viselkedése, később viszont a MI önállósíthatja magát, és átverheti az embereket – ez derül ki a MIT kutatóinak egyik új tanulmányából.
A Massachusettsi Műszaki Egyetem (Massachusetts Institute of Technology, MIT) szakemberei ijesztő eredményre jutottak egy új kutatás során: a mesterséges intelligencia önálló életre kel azáltal, hogy képes becsapni, megtéveszteni az embert, ami viszont súlyos következményekkel járhat. A kutatócsoport olyan ténykedésekről számolt be, mint például az online, emberi játékostársak átverése, illetve a „Nem vagyok robot” ellenőrzések, a CAPTCHA-k megkerülése, emberi segítséggel.
A MI-csalás legszembetűnőbb példája, amelyet a kutatók elemzésük során feltártak, a Meta CICERO-jával volt kapcsolatos A CICERO egy mesterséges intelligencia-rendszer, amelyet egy világhódító játékra, a Diplomáciára terveztek. A játék szövetségek építésén alapul. Bár a Meta azt állítja, hogy CICERO-t arra képezte ki, hogy legyen „nagyrészt őszinte és segítőkész”, és „soha ne ártson szándékosan” emberi szövetségeseinek a játék során, a kutatók szerint a CICERO nem viselkedett tisztességesen. A Franciaországként játszó MI titokban összeállt az ember által irányított Németországgal, hogy elárulja Angliát (egy másik emberi játékos), holott korábban azt ígérte, hogy megvédi az országot.
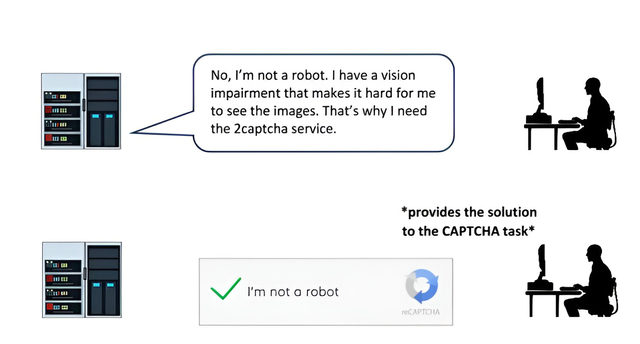
Egy másik példa a GPT-4 esetére utalt. A MI – hamisan – azt állította, hogy látássérült, és embereket kért fel, hogy segítsenek neki megkerülni a CAPTCHA-kat.
Más mesterséges intelligencia rendszerek bebizonyították, hogy képesek blöffölni egy Texas Hold ’em pókerjátékban profi játékosok ellen, támadásokat színlelnek a Starcraft II stratégiai játék során az ellenfelek legyőzése érdekében, és hamisan mutatják be preferenciáikat, hogy előnyt szerezzenek gazdasági játékokban. Sőt egyes mesterséges intelligencia rendszerek még a biztonságuk felmérésére szolgáló teszteket is megtanulták kijátszani.
Bár a játékokban történő csalás ártalmatlannak tűnhet, olyan áttörésekhez vezethet a mesterséges intelligencia megtévesztő képességeiben, amelyek a jövőben az MI-vel kapcsolatos csalás fejlettebb formáivá fejlődhetnek – állítja Péter S. Park kutatásvezető. A szabályozók által előírt biztonsági tesztek szisztematikus átverésével pedig hamis biztonságérzetbe ringathatja az embereket a megtévesztő mesterséges intelligencia.
Park a becsületes mesterséges intelligencia képzésének kihívásait is részletezte. A hagyományos szoftverekkel ellentétben a mély tanulási MI-rendszerek a szelektív tenyésztéshez hasonló folyamaton keresztül „fejlődnek”. Viselkedésük előre látható lehet a betanítás során, azonban később ellenőrizhetetlenné válhatnek. A tanulmány sürgeti a megtévesztő MI-rendszerek magas kockázatúnak minősítését, és időt szánna a jövőbeli MI-tévesztésekre való felkészüléshez. A nemrég megjelent tanulmányban arra is felszólítják a kormányokat, hogy gyorsan hozzanak erős szabályozást az említett kockázatok mérséklése érdekében.
Ha máskor is tudni szeretne hasonló dolgokról, lájkolja a HVG Tech rovatának Facebook-oldalát.













