Ajándékozz éves hvg360 előfizetést!
Ajándékozz éves hvg360 előfizetést!

Időnként mellényúl, de azért már most is sok mindent ért meg képeinkből a Facebook háttérrendszere. Az algoritmusok ugyanis minden feltöltött fotót elemzésnek vetnek alá. Ez egyrészt társadalomjobbító program, másrészt viszont újabb útja annak, hogy a felhasználók adatait használva még több pénzt csikarjon ki a reklámozó vállalatokból a Facebook.
Hogyan lesz túracipő a kovácsoltvas szecessziós liftaknából? A Facebook mesterséges intelligenciája segítségével. A Zuckerberg-birodalom képfelismerő algoritmusai gúnyolódásunkat és gyanakvásunkat egyaránt kiválthatják – indítsunk az elsővel. Az apropó a Facebook múlt heti üzemzavara, amikor pár óra hosszat a fotók egy része nem jelent meg, így láthatóvá vált az a helyettesítő szöveg (Alt Text), amely egyébként évek óta folyamatosan gyártódik, csak a felhasználók zöme mindeddig nem látta.


Ilyesmik bukkantak elő: „A képen a következők lehetnek: égbolt, híd, cipő, túra/szabadtéri és víz” vagy „virág és növény”. A Facebook 2016 óta alkalmazza ezt a címkézést, a hivatalos indokolás szerint azért, hogy segítsen a látáskorlátozottaknak megérteni a fényképek és videók tartalmát (a segítséghez felolvasó alkalmazásra is szükség van). Ez többnyire nyilván hasznos is, de hát a képfelismerés még a technika mai állása mellett is távol van a tökéletestől. Erről ki-ki meggyőződhet, ha próbát tesz a Facebookra feltöltött saját fényképeivel. A fotóknál (másokénál nem, csak a sajátjainknál) a Lehetőségek menüből lehet kiválasztani a „Helyettesítő szöveg módosítása” opciót, és akkor láthatóvá válik, hogyan értelmezte a képet a mesterséges intelligencia. Ha valaki szeretné, felülírhatja az ajánlott címkézést.
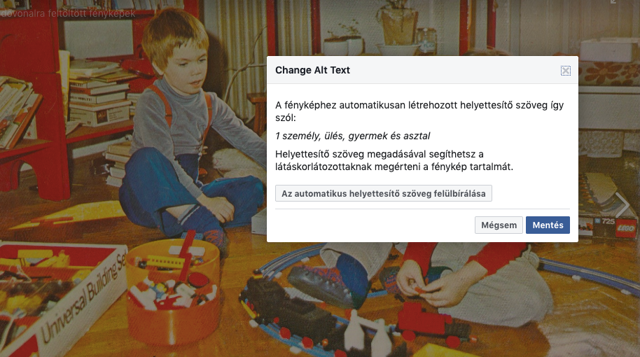
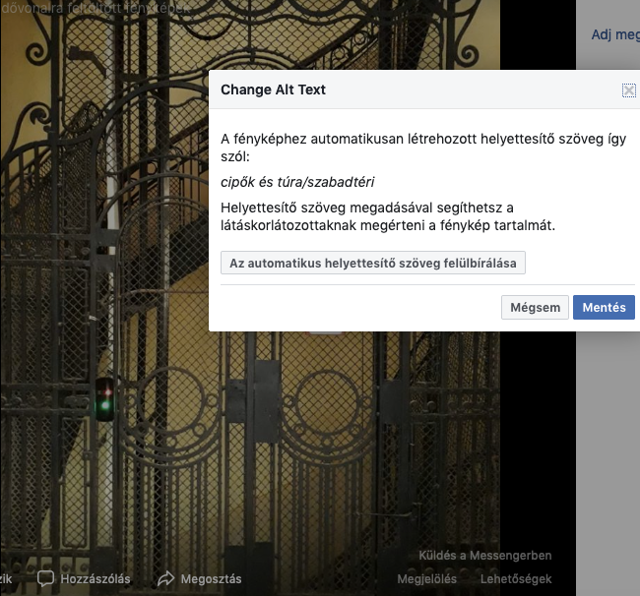
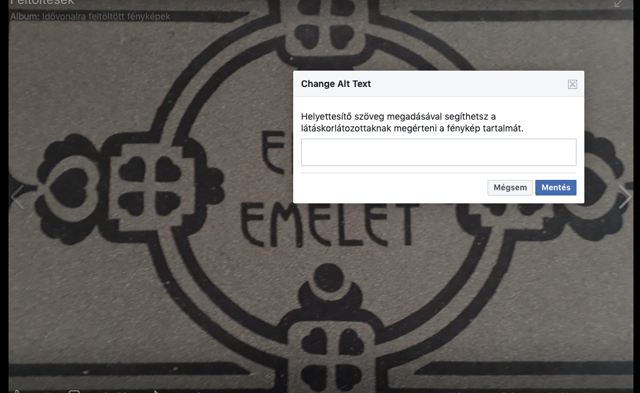
A mi amatőr képeink közül a legszórakoztatóbb, bár ártatlan mellényúlás a „cipők és túra/szabadtéri” magyarázat volt az említett (beltéri és teljesen lábbelimentes) lépcsőházi csendélet esetében. Az algoritmus ráadásul egyszerűen „feltette a kezét” az ugyanott fotózott „első emelet” felirat, illetve máshol egy retró írógép láttán.
Viccnek rossz lenne
Ez eddig csak vicces – véresen komoly volt viszont, amikor a márciusi új-zélandi mészárlás tettese úgy sugározhatta élő videóját a merényletről, hogy a Facebook erre hivatott, mesterséges intelligencia alapú szűrője nem figyelt fel a tilalmas tartalomra. Pedig az lett volna a dolga, hogy ne kelljen bejelentésre, majd emberi ellenőrzésre várni, hanem a veszélyes tartalom eleve föl se töltődjön.
Persze, hogy nem sokkal később, a Facebook szokásos májusi fejlesztői konferenciáján, az F8-on erről kellett beszélniük a Facebook-főnököknek. Mike Schroepfer műszaki igazgató kincstári optimizmussal azt mondta, hogy a cég platformjain (azért a többes szám, mert hozzájuk tartozik az Instagram is) teljesen automatikusan ellenőriznek minden tartalmat, és „a legtöbb esetben magas találati aránnyal” (hogy ez mihez képest mennyi, azt nehéz lenne kitalálni) kiszűrik a nemkívánatos dolgokat.
Nem csak néz, lát is
A technika kétségkívül impozáns. A Facebook kidolgozott például egy olyan objektumfelismerő rendszert – Panoptic FPN néven –, amely nemcsak a személyeket és tárgyakat regisztrálja, hanem a hátteret is, hátha így egyértelműbben értelmezhetőek a képek. A szövegeket a számítógépes nyelvészet korszerű eszközeivel általános digitális nyelvre fordítják, hogy az ártalmas mondatokat több nyelven felismerhessék. A LASER szoftver majdnem száz nyelven tud, és húszfajta ábécét ismer.
A mesterséges intelligencia okosításához akaratlanul hozzájárulnak a felhasználók is. A gyakorláshoz 3,5 milliárd olyan fotót használtak fel, amelyeket a facebookozók nyilvánossá tettek, és címkékkel láttak el. Ennek alapján alakultak ki a kategóriák tízezrei. Ha jó formában van, a mesterséges intelligencia nemcsak a fákat vagy ételeket ismeri fel, hanem azoknak a fajtáját is.

Legalábbis vitatható hozzájárulás viszont, amit májusban a Reuters brit hírügynökség derített ki. Indiában dolgozó külsős munkatársak népes csoportja 2014 óta elemzi a Facebookon megjelenő privát közléseket: miről szólnak, milyen alkalomból íródtak, milyen érzelmeket tükröznek, melyik városból származnak. A cél, hogy a mesterséges intelligenciát továbbképezzék abban, amiben a leggyengébb: a nyelvi finomságok megértésében. Erre nagy szükség is lenne például a hamis hírek és az ironikus megjegyzések elkülönítéséhez.
Életet vagy pénzt
Akár a gyűlöletbeszéd ellen, akár a pornográfia vagy a terrorizmus kiszűrésére, akár a látásukban korlátozottak támogatására, sőt az öngyilkosságok megelőzésére szolgál a képeket és szövegeket elemző mesterséges intelligencia, a célok vitathatatlanul helyesek és közérdekűek. A bevezetőben említett gyanakvást ettől függetlenül kiválthatja a minduntalan – a múlt heti malőr kapcsán is – sok helyen felvetődő kérdés: nem szolgál-e reklámcélokat is a fotók felcímkézése? Hiszen ha egy felhasználó sok fotóját automatikusan kategorizálják, abból már sokat meg lehet tudni az illető érdeklődéséről, szokásairól.
A gyanút erősítheti a Facebook egy szabadalma is. Még akkor is, ha a technológiai cégek szabadalmainak nem elhanyagolható része nem feltétlenül válik valóra, például mert csak piaci célokat szolgál. Néhány hónapja mégis feltűnést keltett az a szabadalom, amelynek címe a szponzorált történetek képi tartalomelemzésére utal. A Fast Company amerikai magazin példája szerint ez azt jelentheti, hogy ha valaki olyan szelfit oszt meg az Instagramon, amelyen az illető a Starbucks kávézóban látható, akkor a Facebook kiszűrheti ezt az információt a képből, és értesítheti a Starbucksot, hogy hol érdemes többet hirdetnie.
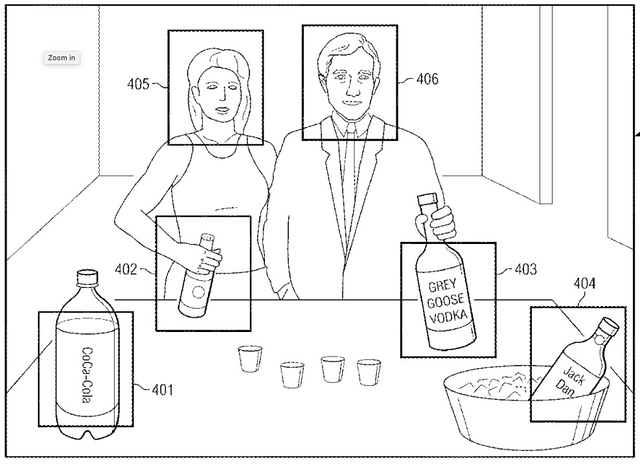
Mindezt úgy, hogy a felhasználó be sem jelentkezett a kávézóba, és nem is címkézte fel a szelfijét. A szabadalmi leírásból az is kiderül, hogy az eljárással nemcsak egy vodkásüveget, hanem a vodka márkáját is fel lehet ismerni, valamint ez párosítható az ilyen vodkát posztolók életkorával, lakóhelyével. Így már egészen célzottan lehet a megfelelő csoportoknak nyomni a reklámokat.
Ha máskor is tudni szeretne hasonló dolgokról, lájkolja a HVG Tech rovatának Facebook-oldalát.