 Ajándékozz éves hvg360 előfizetést!
Ajándékozz éves hvg360 előfizetést!
Az Abbyy FineReader Express Edition Maces változatával pillanatok alatt alakíthatunk át...
Az Abbyy FineReader Express Edition Maces változatával pillanatok alatt alakíthatunk át beszkennelt dokumentumokat, újságoldalakat, táblázatokat a nekünk megfelelő formátumra.
Egy újságcikkből például kinyerhetjük pusztán a szöveget és elmenthetjük azt szerkeszthető RTF dokumentumként, készíthetünk belőle viszonylag tördeléshű weboldalt, vagy éppen kereshető szöveget tartalmazó, de az eredetivel megegyező kinézetű PDF fájlt.
A program használható minden Twain-kompatibilis szkennerrel, de ha már eleve képfájlként van meg az átalakítani kívánt anyag, azt is alapul vehetjük.
Korábban már írtunk a FineReader windowsos verziójáról, és már arról is megállapítottuk, hogy megbízható, és sokoldalú alkalmazás.
A Maces változat - az Express jelzőhöz hűen - még egyszerűbben használható, viszont némileg kevesebbre képes.
Igazi hiányossága tulajdonképpen csak kettő van: az egyik, hogy a vegyes, vagyis képet és szöveget is tartalmazó oldalakat nem tudja úgy szerkeszthető Word dokumentummá alakítani, hogy legalább nagyjából megmaradjon az eredeti tördelés. Az ok egyszerű: RTF vagy TXT formátumot választhatunk csak. Utóbbiban ugye eleve nehéz lenne képet beilleszteni, az RTF pedig alkalmatlan a formahű tárolásra. Így ezzel a módszerrel inkább csak a szöveg tökéletes szerkeszthetővé tételére nyílik módunk. Dokumentumok, könyvek szerkeszthetővé tételére viszont tökéletes. Ha táblázat is van a szövegben, azt gond nélkül felismeri és rekonstruálja a szerkeszthető változatban is.
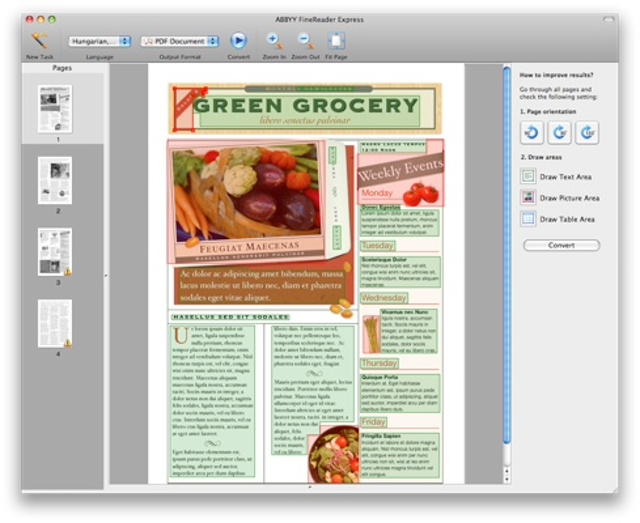
Kis csalással egyébként azért van esélyünk az elrendezést megtartó felismertetéshez, mégpedig úgy, hogy HTML formátumba kérjük a konvertálást. Ilyenkor a program külön elmenti a képeket, és elkészíti a megfelelő HTML dokumentumot, amelyet azután vagy feltehetünk az internetre, vagy adott esetben szerkeszthetünk is megfelelő programmal, vagy ma már szinte minden szövegszerkesztővel. Ha bonyolult, vízjeleket háttérképeket alkalmazó anyagot szkenneltünk, akkor a hasonlóság azért nem lesz tökéletes.
A kereshető PDF dokumentummá konvertálásnál némileg csal a program, de jó szándékkal. Például egy szkennelt újságoldalt tökéletesen olyannak fogunk látni PDF változatban, amilyen az eredeti volt, a különbség az lesz, hogy a szövegek és táblázatok kijelölhetők, szövegként másolhatók, kereshetők lesznek. Az, hogy a PDF a megszólalásig hasonlít az eredetire, annak köszönhető, hogy valóban az eredeti képet látjuk. A szerkeszthető szöveg külön rétegen van (természetesen ha vágólapra másoljuk, megtartja a felismert formázásokat). Ha viszont különleges karaktereket is felismertettünk, amelyekkel valamiért nem birkózott meg a program (ez amúgy rendkívül ritka eset), akkor könnyen lehet, hogy a PDF-ben látott és kijelölt szöveg és a vágólapra másolt bizony nem egyezik. Vágólapra ugyanis már a rosszul felismert szöveg kerül.
Mindenesetre ez a végkifejlet ritkán fordul elő, de ha mondjuk mégis, akkor például olyankor, ha egy különleges karakterkészlettel szedett címet eredetileg képként ismert fel a program, de mi - mivel erre van lehetőség az automatikus felismerési procedúra után - ráerőszakoljuk, hogy az adott területet szövegként kezelje.
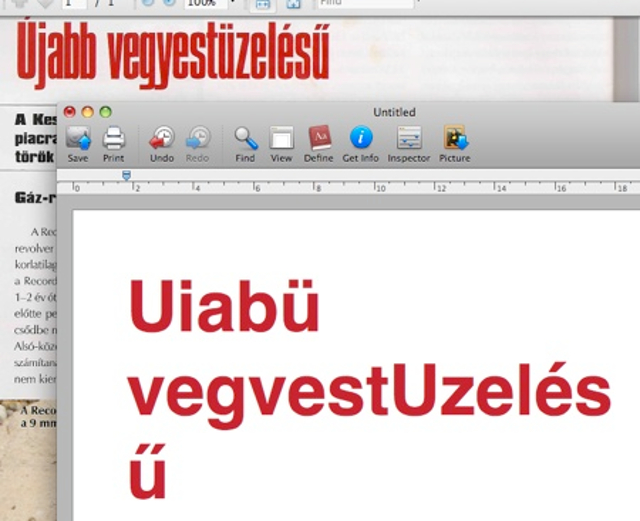
Amúgy az esetek többségében a FineReader Express könnyen felismeri a szövegeket - természetesen a magyar szövegeket is, hiszen 171 nyelvvel megbirkózik -, és ha jó minőségű a szkennelt anyag (minél nagyobb a DPI szám és minél tisztábban kivehető szöveg), a program problémamentesen felismer mindent. 200-300 DPI a sima szövegfelismeréshez bőségesen elegendő (bár a korábbiak ismeretében ezt el is vártuk egy Abbyy terméktől).
A programban külön lehetőség van a táblázatok felismertetésére, ilyenkor a végeredményt Excel formátumban kapjuk meg. A tesztek során ez tökéletesen működött (értelemszerűen a képleteket azért nem tudta kitalálni a nyomat alapján, de a táblázatot tökéletes, szerkeszthető formában kaptuk vissza a táblázatszerkesztőben).
Két hiányosságot említettünk az elején, de eddig csak az egyikről beszéltünk. A másik hiányzó funkció abból adódik, hogy FineReader Express for Mac a cég „light” sorozatát képviseli, így hiányzik belőle a tanítási lehetőség. Vagyis a rosszul felismert karakterek esetében nem taníthatjuk meg a szoftvert, hogy mi lenne a helyes megoldás, így később, ha ugyanabba a problémába ütközik, az eredmény is azonos - adott esetben rossz - lesz.
A felismerés után a program automatikusan menti az eredményt, de ha kedvünk tartja, van lehetőség manuálisan is megadni a kép-szöveg-táblázat területeket. Nálunk a tesztek során még a képekre írt képaláírásokat is gond nélkül felismerte a program, egyedül néhány kacifántosabb fontot használó cím esetében voltak gondjai (ezek többnyire egybeérő karaktereket is tartalmaztak). A magyar ékezetes betűkkel is könnyedén elboldogult.
Egyszerre több fájllal is dolgozhatunk benne, így lehetőség nyílik például PDF fájlok összefűzésére is.
A FineReader Express for Mac tökéletesen Mac-esre sikerült: átlátható, ízléses felületet kapott, és rendkívül egyszerű vele dolgozni (ráadásul gyors is). Egyszer persze szívesen látnánk belőle egy Professional változatot is Macre...
Addig is, ha gyakran kell dokumentumokat átalakítanunk nyomtatott anyagból szerkeszthető szöveggé vagy éppen formahű, kereshető PDF formátummá, akkor érdemes beruháznunk 89 eurót a FineReader Express for Mac-re.



PDF fájlok megnyitása és szerkesztése OpenOffice.org-ban

Szövegkivonás pdf-ből a lehető leggyorsabban, Reader nélkül

Így készíthet PDF fájlt JPEG képeiből, egy dobással, ingyen

Nem kell többé gépelnie!












