Ajándékozz éves hvg360 előfizetést!
Ajándékozz éves hvg360 előfizetést!
A történelem egyik tanulsága, hogy egy új innováció korai fázisának hibái idővel kiküszöbölhetők, és később már egy fejlettebb változatban lesz majd hozzáférhető. Részlet a Mesterséges intelligencia 2041 című könyvből.
Minden nagy erejű technológia kétélű kard. Az elektromosság az eszközeinket energiával látja el, de ha közvetlenül megérintjük, az halálos ránk nézve. Az internet mindent kényelmessé tesz, azonban lerövidíti a figyelem fenntartásának átlagos hosszát. Mik lennének tehát a mélytanulás hátrányai?
| Mi a mélytanulás? |
Sokan azt feltételezik, hogy a mesterséges intelligenciát az emberek „tanítják be” meghatározott szabályokkal és konkrét dolgokra, mint amilyen az, hogy „a macskáknak hegyes a fülük, és bajuszuk van”. A mélytanulás azonban jobban működik az ilyen külsőleg betáplált, emberek által megfogalmazott szabályok nélkül. Terelgetés helyett egy jelenség számos példáját táplálják be egy mélytanulási rendszer bemeneti rétegébe, a kimeneti rétegbe pedig a „helyes választ”. Így a bemeneti és a kimeneti réteg közötti hálózat „megtanítható” rá, hogy maximalizálja a helyes válasz megadásának esélyét egy meghatározott bemeneti adat mellett. Képzeljük el például, hogy a kutatók meg akarják tanítani a mélytanuló hálózatot arra, hogy különbséget tegyen azok között a képek között, amelyeken van, és amelyeken nincs macska. Kezdetben egy kutató több millió képet ad meg bemenetként, amelyet „macska” és „nem macska” címkékkel lát el. A kimeneti rétegnél már előzőleg megadta, hogy „macska” vagy „nem macska” eredmény lehet. A hálózatot megtanítják arra, hogy magától rájöjjön, a sok millió képen milyen jellemzők alapján különböztetheti meg a leginkább a „macskát” és a „nem macskát”. Ez a tanulás egy matematikai folyamat, amely beállítja a mélytanuló hálózat milliónyi (olykor akár milliárdnyi) paraméterét. A folyamat során a mélytanulást matematikailag trenírozzák, hogy egy „célfüggvényre” maximalizáljon. A macskafelismerés esetén a célfüggvény a „macska” vagy „nem macska” helyes felismerése. Amikor elvégezte a „tanulást”, a mélytanuló hálózat tulajdonképpen egy gigantikus matematikai egyenletté alakul, amelyet immár olyan képeken is tesztelni lehet, amelyeket még soha nem látott. 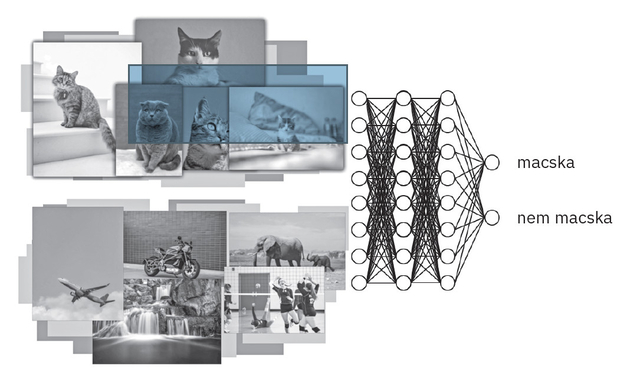 A mélytanuló neurális hálózat megtanulja felismerni a különbséget a macskát ábrázoló és a macskát nem ábrázoló képek között HVG Könyvek |
Az első annak kockázata, hogy az MI jobban ismer minket, mint mi saját magunkat. Az előnyök egyértelműek – az MI képes felkínálni nekünk az általunk vágyott termékeket, mielőtt még bárhol máshol rákerestünk volna. Vagy képes hozzánk illő romantikus párkapcsolati jelöltet vagy barátokat ajánlani a már megismert érdeklődési körök alapján. Ha viszont valakit túlságosan ismer az MI, annak árnyoldala is van.
Megtörtént-e már velünk, hogy leültünk megnézni egy videót a YouTube-on, aztán azon kaptuk magunkat, hogy három órája ott ülünk? Vagy hogy egy provokatív linkre kattintottunk a Facebookon, ami egy még extrémebb tartalomhoz vezetett? Egy 2020-as dokumentumfilm, a Társadalmi dilemma jól ábrázolja, hogy az MI-féle személyre szabás tudtukon kívül manipulálja az embereket a hirdetési bevételek érdekében.
A film egyik szereplője, Tristan Harris egykori Google-alkalmazott, az etikus technológia szószólója szerint senkinek sincs fogalma arról, hogy a kattintása egy szuperszámítógép figyelmét irányítja az agyára. Minden egyes kattintása aktivál egy sok milliárd dollárt jelentő számítógép-teljesítményt, amely már rengeteget tanult arról, hogyan vegyen rá kétmilliárd „emberi állatot” arra, hogy újra kattintson. Ez a függőség ördögi körré válik a felhasználó és a nagy internetes vállalatok számára, csakhogy az utóbbiak mindezt egy jól működő pénzgyárként fogják fel.
A Társadalmi dilemma szerint ez még oda is vezet, hogy leszűkül a nézőpont, polarizálódik és megosztott lesz a társadalom, eltorzul az igazság, valamint csökken a boldogság, romlik a kedélyállapot és a mentális egészség is. Technikailag a probléma lényege a célfüggvény végletes leegyszerűsítése, és annak veszélye, hogy egyetlen célfüggvény szerint történik az optimalizáció. Ez ugyanis káros külső következményekhez vezethet. A mai MI-k általában egyetlen célkitűzésre optimalizálnak – legáltalánosabban arra, hogy pénzt keressenek (avagy több kattintást, hirdetést, árbevételt érjenek el). Az MI pedig mániákusan fókuszál erre az egy vállalati célkitűzésre anélkül, hogy figyelembe venné a felhasználók jóllétét.
Hogyan oldhatjuk meg ezt a problémát?
Az egyik általános megközelítés, hogy megtaníthatnánk az MI-t, hogy komplex célfüggvényekkel dolgozzon. Amikor annak az időnek a maximalizálásáról van szó, amit az emberek a közösségimédia-oldalakon töltenek, Tristan Harris például azt javasolja, hogy egy „jól eltöltött idő” mérőszámot használjunk a csupán „eltöltött idő” helyett. Ezt a két célt egybe lehetne olvasztani egy komplex célfüggvényben.
Egy másik megoldás, amelyet az MI-szakértő Stuart Russell vetett fel, miszerint gondoskodjunk róla, hogy minden célfüggvény az emberek javát szolgálja. Ezt oly módon lehet elérni, hogy az embereket bevonjuk azok tervezésébe. Példának okáért kialakíthatnánk egy „az emberiség jóléte” célfüggvényt, amibe beletartozna a boldogságunk is. Vajon bevonhatnák az embereket annak meghatározásába és címkézésébe, hogy mit jelent ténylegesen a boldogság?
Mindezek a felvetések további MI-kutatásokat igényelnek a célfüggvényekről és arról, hogyan lehet számszerűsíteni és mérni olyan fogalmakat, mint a „jól eltöltött idő”, az „igazságosság” vagy a „boldogság”. Ezek a megoldások ráadásul mind azt eredményeznék, hogy a vállalatok kevesebb pénzt fognak keresni. Hogyan lehetne tehát rávenni a cégeket, hogy érdekük legyen helyesen cselekedni? Az egyik lehetőség, hogy a kormányoknak kellene szabályozniuk mindezt, és megbüntetni a szabályszegést. Egy másik pedig, hogy bátorítani lehetne a pozitív viselkedést a vállalati társadalmi felelősségvállalás (CSR) részeként.
További megoldás lehetne, ha harmadik felek felvigyázóként vennének részt a folyamatban, és a vállalatok teljesítményét statisztikai kimutatásokkal tennék nyilvánossá. Így nyomon követhetővé válnának az olyan mérőszámok, amik például a vállalat által generált „álhíreket” (fake news) vagy a „diszkrimináció vádja miatti peres ügyeket” összegzik. Ezekkel rá lehetne szorítani a cégeket, hogy ők maguk is kezdjenek el a felhasználók érdekeit szem előtt tartó mérőszámokkal dolgozni. Végezetül, talán a legnehezebben megvalósítható megoldás, ha gondoskodunk róla, hogy az MI tulajdonosának érdekei száz százalékban össze legyenek hangolva a felhasználókéival.
Az MI is lehet részrehajló
| MI 2041 - A jövőben történt (podcast) |
| A mesterséges intelligencia (MI) sokak számára egy érthetetlennek tűnő, hatalmas rendszer, de mint minden más, ez is elkezdődött valahol. A HVG Könyvek podcastsorozatában szakértők segítségével járták körbe, mit tartogat nekünk, embereknek a jövő, és mi lesz, tíz, esetleg húsz év múlva. A sorozat epizódjait itt érheti el. |
Egy másik lehetséges hátrány a méltányossághoz és az elfogultsághoz kapcsolódik. Döntéseit az MI tisztán az adatokra és az eredmény optimalizálására alapozza, ezek pedig gyakran kiegyensúlyozottabbak lehetnek azoknál, amelyeket emberek hoznak, akiket befolyásolhatnak az előítéleteik.
Vannak okok, amelyek azonban az MI-t is részrehajlóvá tehetik. Például ha az MI betanítására használt adatok elégtelenek vagy nem reprezentálják jól a demográfiai sokszínűséget az etnikumok vagy a társadalmi nemek szempontjából. Egy vállalat toborzással foglalkozó részlege észreveheti, hogy az MI-jük elfogult a nőkkel szemben, mert a mintaadatok a tanulás szakaszában nem tartalmaztak elég nőkre vonatkozó adatot. Az adatok részrehajlók lehetnek amiatt is, hogy egy részrehajló társadalomból gyűjtötték be őket.
A közelmúltban a kutatások megmutatták, hogy az MI elég nagy pontossággal képes kikövetkeztetni a szexuális orientációt az arckifejezés mikrojellemzőiből. Ez a képesség már önmagában diszkriminációhoz vezethet. Ezek a méltánytalan kimenetelek nem szándékosak, mégis súlyos következményekkel járnak. Amennyiben egy társadalom ezeket a technológiai megoldásokat olyan területeken alkalmazza, mint a kórházi ellátás vagy a bűnügyi igazságszolgáltatás folyamata, úgy a tét még ennél is nagyobb.
A méltányosság és az elfogultság problémáinak megoldása az MI-vel kapcsolatban komoly erőfeszítést igényel. Vannak egyértelmű lépések. Az első, hogy azok a cégek, amelyek MI-t használnak, nyilvánossá kell tegyék, hogy hol használnak MI-rendszereket és milyen célból. Másodszor, az MI mérnökeit ki kell képezni egy sor standard elv szerint – mint ahogyan egy beiktatott orvosnak is le kell tenni előbb a hippokratészi esküt, úgy nekik is meg kell érteniük, hogy hivatásuk etikai döntések egész sorát ágyazza be a termékekbe. Harmadszor, szigorú tesztelésnek kell történnie, és ezt bele kell építeni az MI tanulási eszközei közé. Negyedszer pedig új törvényeket kell hozni, amelyek megkövetelik az MI-k átvilágítását.
A végső probléma a magyarázat és az igazolás kérdése

Az emberek mindig meg tudják indokolni, miért hoztak meg egy döntést, mert az emberi döntések tapasztalatok szűk körén és megfogalmazható szabályokon alapulnak. A mélytanulás döntései ugyanakkor komplex egyenleteket vesznek alapul, amelyeknek egyenként sokezernyi jellemzője és milliónyi paramétere van.
A mélytanulás „indoklása” tulajdonképpen egy ezerdimenziós egyenlet, amelyet hatalmas mennyiségű adat alapján alakít ki. Ez az „indoka” arra, hogy éppen az adott kimenetet produkálta, amely túl komplex ahhoz, hogy egy ember számára ténylegesen el lehessen magyarázni.
Mégis, számos kulcsfontosságú MI-döntés esetében a törvény vagy a felhasználói elvárás megköveteli, hogy magyarázat is társuljon azokhoz, így nagy erőkkel történő kutatás zajlik jelen pillanatban is, hogy megpróbálják az MI-t átláthatóbbá tenni. Ezt vagy úgy igyekeznek megoldani, hogy ezt a komplex logikát egyszerűbben összefoglalják, vagy pedig új MI-algoritmusokat vezetnek be, amelyek alapvetően könnyebben értelmezhetők az emberek számára is.
A mélytanulás ezen hátulütői jelentős bizalmatlanságot okoztak, amint nyilvánosságra kerültek, ám minden új technológiának van negatív oldala is. A történelem tanulsága, hogy egy új innováció korai fázisának hibái idővel kiküszöbölhetők, és később már egy fejlettebb változatban lesz majd hozzáférhető. Jusson eszünkbe a biztosítékok bevezetése, amelyek segítenek elkerülnünk a halálos áramütést, illetve a vírusirtó szoftverek, amelyek távol tartják a számítógépes vírusokat. Bizonyos vagyok benne, hogy lesznek megfelelő irányelvek és szabályozások, valamint technológiai megoldások, amelyek választ adnak majd az MI befolyásoló, részrehajló és átláthatatlan működéséből fakadó kihívásokra.
A fenti cikk a Mesterséges intelligencia 2041 című könyv szerkesztett részlete.
Elképzelhető-e, hogy a mesterséges intelligencia jobban ismerjen minket, mint mi saját magunkat? Jogában és hatalmában áll-e majd a gépeknek az emberi élet kioltásáról dönteni? Könyvében Li Kaj-fu, a Google China korábbi elnöke és Csen Csiu-fan sci-fi-író tíz izgalmas novellában és a történeteket kísérő elemzésben mutatja be vízióját arról, milyen lesz a világ 2041-ben. A könyvet itt rendelheti meg kedvezménnyel.



A robotok egyelőre nem veszik el a munkánkat, de érdemes résen lenni